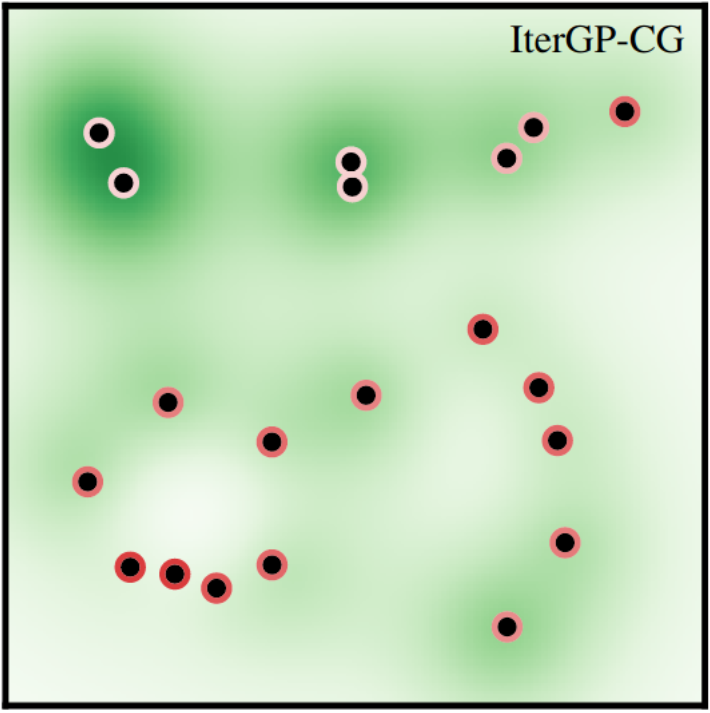
 Computational uncertainty after four iterations of our Algorithm. Computational uncertainty is small in parts of the input space where there is either no data or computation was targeted already.
Computational uncertainty after four iterations of our Algorithm. Computational uncertainty is small in parts of the input space where there is either no data or computation was targeted already.Abstract
Gaussian processes scale prohibitively with the size of the dataset. In response, many approximation methods have been developed, which inevitably introduce approximation error. This additional source of uncertainty, due to limited computation, is entirely ignored when using the approximate posterior. Therefore in practice, GP models are often as much about the approximation method as they are about the data. Here, we develop a new class of methods that provides consistent estimation of the combined uncertainty arising from both the finite number of data observed and the finite amount of computation expended. The most common GP approximations map to an instance in this class, such as methods based on the Cholesky factorization, conjugate gradients, and inducing points. For any method in this class, we prove (i) convergence of its posterior mean in the associated RKHS, (ii) decomposability of its combined posterior covariance into mathematical and computational covariances, and (iii) that the combined variance is a tight worst-case bound for the squared error between the method’s posterior mean and the latent function. Finally, we empirically demonstrate the consequences of ignoring computational uncertainty and show how implicitly modeling it improves generalization performance on benchmark datasets.
Jonathan Wenger
Postdoctoral Research Scientist
My research interests include probabilistic numerics, numerical analysis and Gaussian processes.