On the Disconnect Between Theory and Practice of Neural Networks: Limits of the NTK Perspective
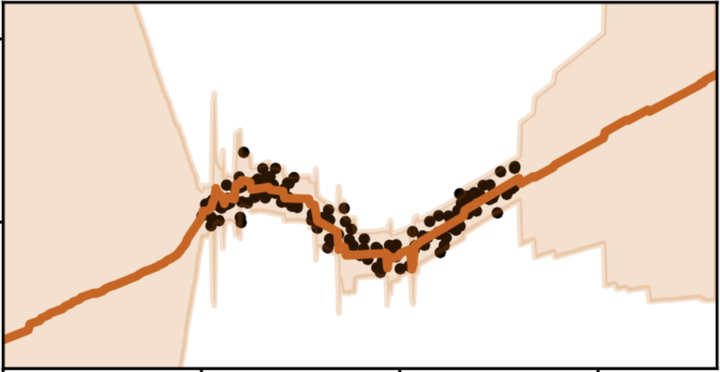 Infinitely-wide neural networks in theory and their finite-width approximations in practice learn significantly different functions.
Infinitely-wide neural networks in theory and their finite-width approximations in practice learn significantly different functions.Abstract
The neural tangent kernel (NTK) has garnered significant attention as a theoretical framework for describing the behavior of large-scale neural networks. Kernel methods are theoretically well-understood and as a result enjoy algorithmic benefits, which can be demonstrated to hold in wide synthetic neural network architectures. These advantages include faster optimization, reliable uncertainty quantification and improved continual learning. However, current results quantifying the rate of convergence to the kernel regime suggest that exploiting these benefits requires architectures that are orders of magnitude wider than they are deep. This assumption raises concerns that architectures used in practice do not exhibit behaviors as predicted by the NTK. Here, we supplement previous work on the NTK by empirically investigating whether the limiting regime predicts practically relevant behavior of large-width architectures. Our results demonstrate that this is not the case across multiple domains. This observed disconnect between theory and practice further calls into question to what degree NTK theory should inform architectural and algorithmic choices.
Jonathan Wenger
Postdoctoral Research Scientist
My research interests include probabilistic numerics, numerical analysis and Gaussian processes.